Table of contents
Introduction A New Arrangement for Cryptographic Data Integrity Factual Summary of the Frogbit Algorithm . . . . Overview . . . . Run Length Process . . . . Index Permutation Process . . . . Key Source Selection . . . . Initialization Procedure An Heuristic Development Process Component Collision AnalysisA few different formulations are given elsewhere for the core Frogbit algorithm, but justification of the algorithm deserves a little more narrative explanation. This is the purpose of the present document.
A stream cipher operates on cleartext messages serially, applying XOR encryption to each message bit. It uses a pseudo-random bit generator (PR generator) for which the seed is derived from the cipher secret key. Our definition of data integrity protection uses the bit-serial characteristic of a stream cipher. Let us assume that a bit-serial cleartext message is encrypted into ciphertext by a sender, and that a session key is established for this purpose (we ignore attacks based on different messages that could be encrypted with the same key). The legitimate receiver decrypts the ciphertext and gets the recovered cleartext. An adversary is given the opportunity to modify the ciphertext bits in transit from the sender to the receiver.
It is easy to turn a cryptographic scheme strictly conforming to this
definition into a scheme where any modification of the ciphertext has
at most a
2-L probability of remaining undetected by the legitimate receiver:
simply append
L bits of redundancy to the cleartext message (e.g.
L bits set to zero), and have the legitimate receiver check their
presence before accepting the recovered cleartext as genuine. We assume
that the adversary neither cuts nor extends the ciphertext bit string,
but such a concern may be adressed with other forms of simple message
redundancy (e.g. a cyclic redundancy check).
We are now ready to describe the arrangement intended to provide the data integrity protection as defined. This is illustrated in figure 1. This figure is concrete with respect to the double XOR encryption applied serially to each cleartext message bit. This double encryption creates the inner sequence (the intermediate result in the double XOR encryption), with the useful property that the adversary can not alter the cleartext bit without altering the inner sequence bit.
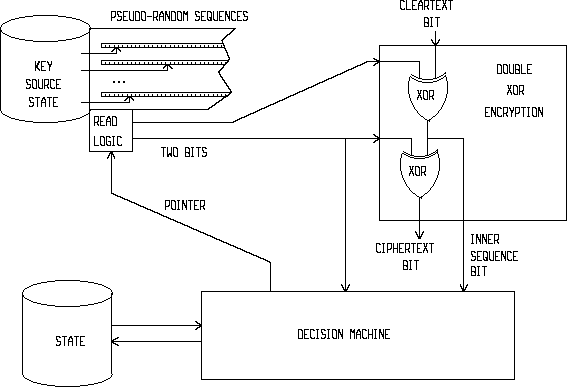
The other parts of the figure 1 show a more generic and abstract view of actual schemes providing data integrity protection. The key store with its read logic represents the supply of random or pseudo-random bit pairs to the double XOR encryption. Secrecy is achieved by hiding the contents of the key store for the adversary. At the abstract level, the key store has no state information, and an explicit address or pointer value is provided independently for each bit pair to be retrieved (e.g. if the key store was implemented by a sequential PR bit generator, the abstract pointer moves by two bit positions at each step). The data integrity protection is provided by a properly designed decision machine. The only part of the arrangement that maintains state information is the decision machine. It has two independent inputs, both being unknown to the adversary: the inner sequence bit, and the key bit used by the second stage of the double XOR encryption. The design goal of the decision machine is to vary the pointer passed to the key store read logic according to past inputs.
The Frogbit algorithm is a practical version of our data integrity arrangement. We developed it with by a trial and error process where adversary attacks were simulated under the most defavourable conditions.
The goal of the Frogbit cipher is to make sure that inverting one bit in the ciphertext (by a defrauder) leads to inverting the corresponding bit of the cleartext (as recovered by the legitimate receiver) plus a permanent change in the rest of the key stream, (and thus the rest of the recovered message is randomized for the legitimate receiver). So the data integrity protection may be provided by the Frogbit cipher with some cleartext message redundancy which should allow the receiver party to detect any such message randomization with high probability. This redundancy may take the form of a simple "exclusive or" checksum of sufficient length appended to the message.
With the Frogbit cipher, each cleartext bit
mi is doubly encrypted by two key stream bits,
k1i and
k2i. The advantage of double encryption is
not strengthened confidentiality. Instead, the double encryption creates
a secret inner sequence bit
si. It is significant that the secret inner sequence bit
si and the second secret key stream bit
k2i, are both (pseudo-)random and (pseudo-)independent of each other.
Moreover, inversing one bit of the ciphertext changes both the cleartext
recovered by the legitimate receiver (according to the encryption
equation
ei=k1i XOR mi XOR k2i) and the inner sequence (according to the equation for inner sequence
si).
The permanent change in the rest of the key stream comes from the
variations of subsequent key stream bits
k1i+1 and
k2i+1, key stream bits
k1i+2 and
k2i+2, and so on, by a decision machine having finite state information and
two inputs, respectively the secret inner sequence bit
si and the second secret key stream bit
k2i. Suitable decision machines are such that it is hard to find a
collision, that is two message substrings
mi,mi+1,...,mi+k-1 and
m'i,m'i+1,...,m'i+k-1
that start and end with the same state information in the decision
machine. The core Frogbit algorithm is one such decision machine. There
are three intermixed components in the core Frogbit algorithm:
The term run length encoding refers to a coding or compression method
based on counting consecutive repeated values in a message. For the
Frogbit cipher, the run length encoding is applied to bits
si of the inner sequence. In the mathematical formulation of the core
Frogbit algorithm, the run length is the function
r(i). In practice, the run length must be bounded by a finite upper limit,
the parameter
n. In the mathematical formulation of the core Frogbit algorithm, the
bounded run length is the function
r'(i). In the mathematical formulation of the core Frogbit algorithm, each
bounded run is marked with
r'(i)=0, and is the occasion for to "draw" a number, that is the
function
d(i). The draw function uses the second half of the key stream
(k2i) to produce the number. The preferred embodiment uses the parameter
n set to 2.
The Frogbit run length process is only the first part of a finite
state machine characterized by its dual input
si and
k2i. The distinctive feature of the core Frogbit specification is that a
change in
si will trigger, with a very high probability, an arbitrary modification
to the following bit pairs
<k1i+1,k2i+1>,
<k1i+2,k2i+2>, and so on.
The index permutation process maintains a table of ten permuted
indexes, that is the function
T(i). When the run length process draws the number
d(i), two things occur: a new index
d'(i) is established as the pseudo-random sequence selector for the next
bit positions, and the index table function
T(i) is updated. The function
i'(i) is merely a function that "points to" the beginning of a
bounded run that finishes at bit position
i.
The permutation table
P is an important source of diffusion for the index permutation
process. The reference permutation table in was selected by a
"fair" pseudo-random program that enforced a number of criteria. It
limited the frequency of a given number in any column of the table (a
limit of three occurrences per column). It forced the permutation of
each row to contain exactly two cycles (e.g. in the first row, positions
0, 2, 5, and 7 are permuted among themselves, as are every other
positions). It didn't allow any cycle of length one. Additional care was
taken to avoid cycles made of the same positions in two different rows.
The ten independent pseudo-random sources need only to meet the
generic requirements to have ten independent pseudo-random sequences
securely derived from a secret key (without knowledge of the secret key, it
is computationally infeasible to guess any portion of any sequence, or
any correlation between any two sequences). The pseudo-random
sequences are independently utilized by the Frogbit cipher, one bit at a time:
the utilization (or absence of utilization) of one sequence must not
change the state (e.g. current location within the sequence) of any
other sequence. Then, for each bit
i processed by the Frogbit cipher, the index permutation process
provides an index
d'(i-1) which selects the pseudo-random sequence to utilize for the pair of
bits
<k1i,k2i>.
The Frogbit cipher accommodates any pseudo-random generator which is acceptable as a stream cipher. Moreover, the Frogbit cipher algorithm might be secure even with bad generators, of which security would be questionable if used in a normal stream cipher arrangement. For instance, the LFSR (Linear Feedback Shift Register) is a type of pseudo-random number generator easily implemented in hardware.
A simple initialization procedure for the Frogbit cipher is to set the seeds for the ten independent pseudo-random generators from the secret key. In fact, secret initialization can go beyond the ten pseudo-random seeds: every single element of the Frogbit state can be derived from a secret key. It is thus possible to use diverse conventions for the secret part of the initial state information.
The Frogbit cipher state comprises the following elements: for the run
length processing, 1) the previous bit for the run length processing,
that is
si-1, 2) the current bounded run count, that is
r'(i-1), 3) a partial sum, that is the accumulated binary representation
k2i-r'(i-1),
k2i-r'(i-1)+1, ...
k2i-1 (actually, when
n=2, this is at most a single bit of information); for the index
permutation process, 4) the current permutation table, that is
T(i-1-r'(i-1)); for the key source selection, 5) the current key stream number, that
is
d'(i-1), and finally 6) the state of the ten pseudo-random generators, or the
ten key stream positions.
The number of states for item 6) of the Frogbit cipher state can be viewed as 10 times the count for each pseudo-random generator (for a purely periodic generator, the state count is the period of the generator). Even with the simplest pseudo-random generators, the total is a reasonable figure by current standards of secret key cryptography. Alternatively, for the state of the ten independent key streams, we may focus on the advance of each one. This information is relative to the start of message processing. Then, the state consists of the count of bit pairs extracted from each key stream. These two approaches are applicable respectively to the proprietary algorithms and the hash function.
The design rationales for the core Frogbit algorithm are better described as an ad-hoc heuristic development process than as the refinement of prior research in the field of cryptographic data integrity. Yet, the original incentive for our work was the sparing published work on practical data integrity algorithms in the context of a stream cipher. From the implementor's perspective, it is somehow annoying to implement a block cipher for data integrity services (using the CBC-MAC construct) when a good stream cipher is used for confidentialy services. A representative application occurs in embedded cryptographic applications if a configuration file is stored outside of a tamper-proof enclosure which encompasses little more than the computing core of the apparatus. In this context, the following requirements can be stated:
The actual heuristic development process started with the vague idea that the run length encoding could provide the projection of a single bit modification to adjacent bits in a stream cipher. Every other feature or component was added by a sequential trial and error process, with some empirical measure of progress towards the Frogbit primary objective. In this random search, we did not follow routes with very bad efficiency characteristics. In addition, we stopped when the algorithm on the drawing board appeared to fulfill the requirements. Admittedly, it is possible that the end-result applies in a sub-optimal way some cryptographic properties for which formal definitions and proofs are yet to be found.
For the record, the important aspects of the Frogbit algorithm were put into place in the following sequence:
si and
k2i,
As we headed towards a better looking algorithm, we had to refine our security measurement approach. The obvious weaknesses of early attempts were easily found with manually entered test data. Then, exhaustive search for collisions was used, and we obviously couldn't avoid making use of the birthday paradox of data integrity algorithms (although we were looking for data integrity of encrypted messages, we attempted to observe collisions in the clear). When the residual collisions of our algorithm were not visible with the "resolution" of direct birthday attacks, we reverted to component collision search. We will discuss the concept of component collision in the next section.
There are a couple of ad-hoc verifications which may be applied to the
final Frogbit algorithm, but which can only give negative indications
about its validity. The Frogbit state is a structured piece of
information, something radically different from the familiar set
{0,1}L (binary strings of length
L, to which current data integrity algorithms maps the message space,
e.g.
L=160 for the SHA). Whatever the set of possible Frogbit state is, its
probability distribution is definitely not uniform. We refer to the
probability distribution induced by uniformly sampling messages from the
message space and taking the corresponding final Frogbit state (assuming
a fixed secret key). So, we felt it was necessary to assess the
Frogbit state
entropy associated with the final Frogbit state probability distribution.
Short of a mathematical analysis of our algorithm, we created an ad-hoc
data compression program to assess the typical bit length of
compressed Frogbit final state. At best, this gives an upper limit on the actual
Frogbit state entropy. These experimental results showed bit counts
usually between 108 and 160. Given imperfections in our methodology, we
can not claim that the actual entropy is over 100 bits, but it
shouldn't be too far. This order of magnitude seems consistent with the
stated goal for the Frogbit algorithm.
In a sense, another test is the mere observation of the algorithm efficiency in comparaison with other data integrity algorithms. On bit rate comparaison using a 32 bit computer, the Frogbit algorithm is about four times slower than a fast DES implementation (using S-box cooking and full precomputation of the key schedule). The Frogbit algorithm is relatively more performant on small computers (it processes mainly small values). If the Frogbit algorithm was really fast, this single fact would alone justify an attitude of scepticism. Even if a fast secure hash algorithm existed with the data integrity arrangement of figure 1, it is improbable that our heuristic development methodology would have found it.
At the end of the journey, the heuristic development process gave the core Frogbit algorithm, which fits into the data integrity arrangement shown in figure 1. The algorithm and the arrangement are radically different from prior design principles for cryptographic data integrity solutions. For this reason, the notion of modes of operation has to be revisited in the context of the Frogbit algorithm.
Our strongest validation of the Frogbit algorithm security is
component collision search. Let us use the notation
Gi for the Frogbit state just before the processing of bit
i. A full Frogbit collision is two inner sequence substrings
sc, sc+1, ..., sc+k-1 and
s'c, s'c+1, ..., s'c+k-1 that meets two requirements:
Gc and
Gc+k, and
k2i components (the
k1i components are embedded in the inner sequence bits, the latter being
alterable externally through the ciphertext).
Gc would imply the exact PR sequences used in requirement 2). To be
applicable in practice, a collision must also meet the following
requirement:
Using an analogy with block algorithms, a collision involving partial Frogbit state information is comparable with cryptanalysis of a block algorithm with a reduced number of rounds.
For a collision search, we used the table of permuted indexes as the
core component of the Frogbit state. Indeed, since this table has only
10!=~205 states and 20 different transitions at each update operation, so
collisions are deemed to occur with small number of transitions. For
instance, the permutation rows 14, 9, and 7 lead to the same state of the
index table as the permutation rows 3, 17, and 0. Specialized research
results in the field of graph theory might contribute to the
understanding of the inherent difficulty of finding collisions given the
permutation table and other Frogbit rules.
To find collisions when more components of the Frogbit state are taken
into account, we programmed a simulation with exhaustive search using
a birthday attack strategy. It took about 12 hours of computing time
on a Pentium 75MHz processor to find a collision involving all of the
Frogbit state, except for the sequences of
k2i. In the theoretical perspective where the Frogbit state implicitly
defines the sequences of
k2i, the collision found has identical relative keystream positions, in
the final state
Gc+k, but the absolute keystream positions in the initial state
Gc do not agree. The specific collision occurs from the (randomly
chosen) initial state
Gc where
sc-1=1,
r(c-1)=0,
T(i'(c))={4,1,5,2,0,9,7,8,3,6}, and
d'(c-1)=7; the two alternative sequences of
d(c+i)'s leading to the same final state are
%, 9, %, 4, %, 6, %, 9, %, 6 and
%, 5, %, 8, %, 6, %, 3, %, 2 (undefined
values for
d(c+i) are indicated by %). Exactly two bit pairs are extracted from the PR
generators 5 to 9, and none from generators 0 to 4.
Coming back to our initial definition of data integrity, if we were able to find a complete collision of the core Frogbit algorithm, we could hope to estimate the very small probability that a random alteration of the ciphertext has a limited impact on the recovered plaintext. Our inalility to find such collisions is the strongest validation of the Frogbit algorithm so far. It is as if the PR generators embedded in the Frogbit algorithm were very important for its validity. The combination of a mode of operation with the core Frogbit algorithm should provide another layer of data integrity protection, but analytical cryptanalysis of a given combined specification (Frogbit plus PR generators plus mode of operation) remains possible in theory.
CONNOTECH Experts-conseils Inc.
9130 Place de Montgolfier
Montréal, Québec, Canada, H2M 2A1
Tél.: +1-514-385-5691
Fax: +1-514-385-5900